Creating expressive, diverse and high-quality 3D avatars from highly customized text and pose is a challenging task owing to the intricacy of modeling
and texturing in 3D that ensure details and various styles (realistic, fictional, etc).
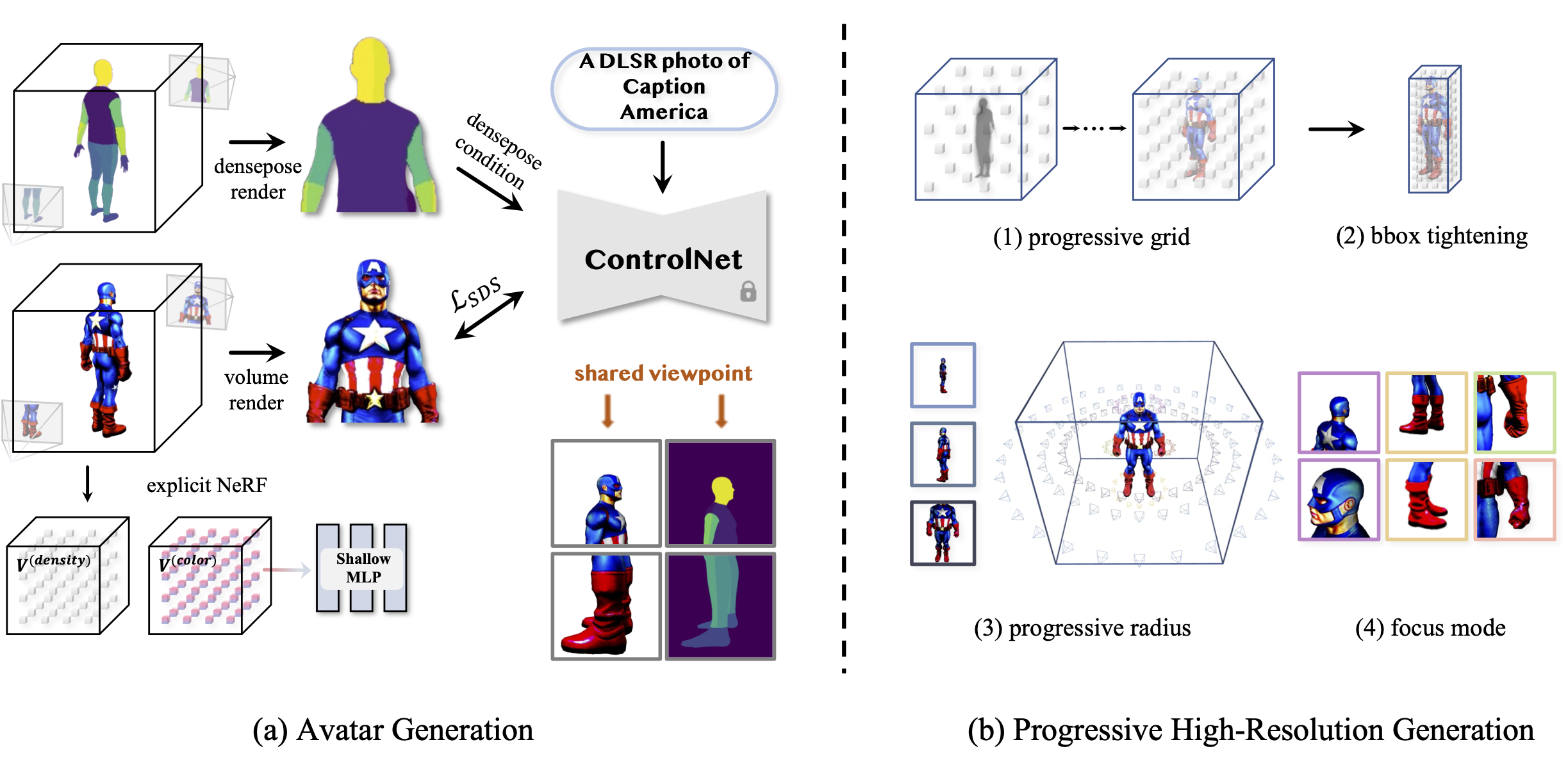
In this project, we present AvatarVerse, a stable pipeline for generating high-quality 3D avatars controlled by both text descriptions and pose guidance.
At the core of the proposed framework, we trained a DensePose-conditioned 2D diffusion model to establish precise and flexible view consistency control between 2d-3d,
even in partial observed scenarios and thus effectively addressing the Janus Problem. Our progressive high-resolution strategies further contribute to a substantial
improvement over the quality of the avatars.
Gallery
Here we demonstrate best-quality Head-Only, Half-Body, Full-Body and Pose-Control 3d avatars generated by our method. Click to play the following animations.
Head-Only
Nick Wilde from film Zootopia
Simba from The Lion King
Master Chief in Halo Series
Elsa in Frozen Disney
Batman
Stormtrooper
Yoda in Star Wars Series
Hannibal Lecter
Monkey D. Luffy
A bearded man with curly hair posing in a black leather jacket
A young man with curly hair wearing glasses
A woman with afro hairstyle wearing red
Half-Body
Spiderman
Link in Zelda
Woody in Toy Story
Buzz Lightyear
Stormtrooper
The Flash
Deadpool
Mobile Suit Gundam
Jake Sully in film 《Avatar》
Albus Dumbledore
a security guard
a karate master wearing a black belt
Full-Body
Stormtrooper
Joker
a Viking
A standing Captain Jack Sparrow from Pirates of the Caribbean
Spiderman
Doctor Strange
Mobile Suit Gundam
Ronald Weasley[, adult]
a person dressed at the Venice Carnival
a body builder wearing a tanktop
a Buddhist monk
a man wearing a white tanktop and shorts
Pose-Control
Iron Man
Thor (Marvel Cinematic Universe) raising a hammer up, brown hair
Spiderman
Hulk
BibTeX
@misc{zhang2023avatarverse,
title={AvatarVerse: High-quality & Stable 3D Avatar Creation from Text and Pose},
author={Huichao Zhang and Bowen Chen and Hao Yang and Liao Qu and Xu Wang and Li Chen and Chao Long and Feida Zhu and Kang Du and Min Zheng},
year={2023},
eprint={2308.03610},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Project page template is borrowed from AnimateDiff.